Chapter 3 Data – Reading, Wrangling, and Writing
This text avoids canned data sets from R packages because importing and wrangling data is a major obstacle in doing statistics for new R learners. Coding the import of raw data archived in text (or Excel or Google sheets) format is a best practice for increasing replicability.
Importing data is difficult for new R learners for two reasons
- Many experimental biology researchers archive the data in a format that might make sense for analysis in Excel, but doesn’t work for analysis in most other statistical software, including R, without significant post-import processing (or wrangling) the data. This includes
- data in wide format, where the measures of the response variable for each treatment level is in a different column
- data in transposed format, where the measures of the response variable are in a row instead of a column (or the measures for each treatment level are in a separate row)
- missing values that are represented by different things, sometimes in the same table. These things include blank cells, periods, hyphens, the word “NA,” or numbers such as -9999.
- column headers that have multiple words separated by spaces
- sheets with a variable number of empty cells that separate values within different groups
- sheets that contain information about the data using colored blocks of cells or other formats
These issues are solved by archiving data in (tidy data format)https://cran.r-project.org/web/packages/tidyr/vignettes/tidy-data.html. The hallmark of tidy data is data in long format, which is introduced in the next section (Section @data-long). Nevertheless, most students and researchers will have colleagues that share non-tidy data and a critical skill for R users is the ability to tidy data.
- A file on a hard drive has an address, or file path that is specific to both place (the specific computer) and time (the file organization of the computer). If we move a data file to another computer, or even to another directory within the same computer, the address changes. Modern computer users are at least vaguely familiar with the hierarchical organization of file storage (most students in my classes seem to store everything they create on the desktop) but are unaware of the concept of a file path and confused by what this path is. When we use a menu-driven system to open a file, the OS is constructing the file path under the hood. But when coding, we need to give R the file path. There are several imperfect methods for coding the path the the data file. There is one perfect method – the function
herefrom the here package. This is discussed in Use the here function to construct the file path
3.1 Long data format – the way data should be
Some best practices for archiving data tables, including archived data at journal websites, are illustrated by the format of the data in Table 3.1.1
| subject_id | institution | diet | vo2 | lean_mass | fat_mass |
|---|---|---|---|---|---|
| D1 | UC Davis | HF | 129.5653 | 24.33708 | 15.862920 |
| D10 | UC Davis | LF | 100.0749 | 21.08880 | 3.151200 |
| D11 | UC Davis | LF | 118.3097 | 22.56076 | 6.659238 |
| D12 | UC Davis | LF | 107.7487 | 22.11884 | 5.351156 |
| D13 | UC Davis | LF | 104.7367 | 21.17438 | 5.005616 |
| D14 | UC Davis | HF | 138.6420 | 24.64885 | 16.501150 |
The best practices included in the archived data include
- The data table contains all measures on each individual. In most of the archived Excel files that I download from journal websites, the researchers have separated each variable into separate tables and exclude all information from these tables other than the treatment group. For example, researchers would typically archive the vo2 values in Table 3.1 in a separate table within an Excel sheet and with the values split by diet group (high fat “HF” and low fat “LF”)(Figure 3.1). Don’t do this.
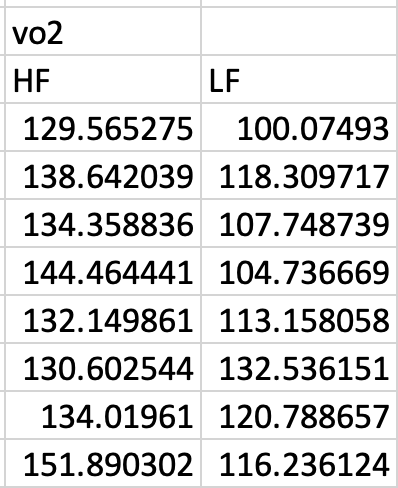
Figure 3.1: The vo2 values separated from the rest of the data and split into separate diet groups.
- We don’t want to separate each variable into separate tables because we often want to use information from other measures of the same individual in our analysis. For example, for the comparison of among treatment levels, we would want to add the measure of to the model as a covariate (what is often called an ANCOVA model). To do this, we’d need to know which values of and values of belong to the same individual.
- Even if you think you have analyzed the data using a best practice, don’t separate each variable into separate tables. Researchers sometimes fail to recognize best practices. Any re-analysis of published data using best practices often require information from other measures of the same individual. For example, many researchers would compare the ratio of to among treatment levels. This isn’t a best practice and if I want to check the researchers conclusions, I’d need a table like Table 3.1 to re-analyze the data.
- Even if you have used what is considered a best practice, don’t separate each variable into separate tables. Sometimes a researcher wants to use data from published data sets to parameterize a mechanistic model. Or, use data from published data sets to explore patterns of relationships among variables, for example how fat mass scales with lean mass (or total mass). For these, we need a table like Table 3.1 to re-analyze the data.
- The researchers organized the table with individuals in rows. A data table with all measures for each individual could organize the data with each row or each column belonging to one individual. The best practice for most analysis in R (and most other statistical software) is to organize individuals to rows (there are exceptions in some R packages that analyze genomics datasets).
- The researchers organized the data in long format – that is, each column contains all measures of a single variable. In general, do not organize the data in wide format, by splitting the values of a variable into multiple columns, with each column representing the values for a different group. An example of wide format is in Figure 3.1, which is the subset of data split by the groups in the columne . By contrast, the data are in long format in the original table (Table 3.1). It might be useful to think of long format for a variable as a single column with the values for each group stacked on top of each other.
In general, R and almost all other statistical software (one exception is Graphpad Prism) require the data to be in long format.
- A reason for this is because the long format is consistent with the math underneath the statistical modeling of data. For example, the least squares solution of the linear model is
where is the model matrix, a table of numeric values with each row containing the values of the variables for an individual (categorical variables such as are recoded into one or more numeric indicator variables indicating group membership). The model matrix is in long format. * A second reason is organizational simplicity. Statistical models often include multiple variables measured on the same individual – the example above with added as a covariate is an example. With data in wide format, there is no non-awkward way to match values of with values of from the same individual. Or, in models with crossed factor variables, for example, an experiment with four groups repesenting all four combinations of the variables (with levels “WT” and “KO”) and (with levels “Control” and “HFD”), there is no non-awkward way (at least in a table with a single header row) to indicate that the design is two crossed factors. In wide format, the design appears to be a single factor with four groups.
Don’t confuse a data table with multiple columns of different variables with a data table in wide format. Long and wide are relevant to how a single variable is organized – if split into multiple columns the table is wide, if stacked into a single column, the table is long.
One exception to long format is a longitudinal or a repeated measures data set (Chapter 17), in which the response variable is measured multiple times on each individual. An example might be a pre-post design where a variable is measured both before and after a treatment is applied or an experiment where the response is measured each week for multiple weeks. In univariate models for the analyses of these data, the multiple measures for an individual are stacked into long format. As a consequence, there are now multiple rows of data for each individual (one for each measure of the variable). In multivariate models for the analyses of these data, the multiple measures for an individual are treated as if they are different variables and are spread out into wide format.
- The table includes the raw values. Many researchers normalize or standarize the values of a variable by constructing a ratio of the raw value divided by some standardizing value. Almost always, the best practice is to leave the response variable alone (do not make a ratio) and include the standardizing value as a covariate (or offset) in the model. But, if I want to check th conclusions of a particular result in which the researchers used a ratio as the response variable, then I would need the raw measures and the standardizing values.
3.2 Use the here function to construct the file path
Importing data into R can be a struggle for new R users and, unfortunately, most online “how to import” sources give easy but superficial methods that don’t follow best practices for increasing reproducibility or do not allow flexible organization of files within a project.
(TL;DR – use here() from the here package)
df <- read.table(file="clipboard")imports data copied to the clipboard, from an Excel/Sheets file or from an open text file. For this to be semi-reproducible, a comment specifying the filename, worksheet and range that was copied is necessary. More problematic (catastrophically so for reproducibility), is, how does a researcher know that they highlighted and copied the correct range in the Excel sheet?df <- read.csv(file.choose())opens the familiar “open file” dialog box, which lets the user navigate to the file of choice. For this to be semi-reproducible, a comment specifying the filename to import is necessary. The catastrophic problem (for reproducibility) is, how does a researcher know which file was actually opened during an R session? The researcher might think they opened “walker_maine_bee_data_clean_androscoggin.csv” but mistakenly opened “walker_maine_bee_data_clean_aroostook.csv.”df <- read.table(file="my_data.txt")anddf <- read_excel(file="my_data.xlsx")are reproducible because the filename is explicitly specified. But, this method requires that “my_data” is physically located in the same folder as the file containing the R script (the .Rmd file in our case) and this violates the best practice of clean project organization with different folders for the different kinds of files (data, R scripts, images, manuscript text, etc.).- R Studio has an elegant import tool in the environment pane that opens a custom dialog box that allows the researcher to navigate to the file, and to specify what part of the file to import, such as the specific sheet and range for an Excel file. This has the same reproducibility issues as #1 and #2 but R Studio includes the equivalent script, which adds all relevant information for reproducility. One then simply copies and pastes this script into a code chunk and voila! The next time the script is run, the data can be imported from the script without using menus and dialog boxes. Except that..the script does not seem to take into account that the working directory of an R Markdown file is not the project folder but the folder containing the R Markdown file and so this two-step method fails. More personally, I’d prefer to run a chunk that quickly opens the data file instead of re-navigating through my file system and re-specifying the sheet and range every time I re-start the project in a new R session.
There are at least three solutions to the issues raised above, all requiring some understanding of file paths and directory structure in an operating system. A file such as “my_data.xlsx” has an absolute file path, which is the full address of the file (the filename is something like your house street number). The absolute file path of “my_data.xlsx” might be “/Users/jwalker/Documents/applied-biostatistics/data/my_data.xlsx.” A relative file path is the file path from the working directory. In an R Studio project, the working directory is the project directory, which is the directory containing the .Rproj file. This will be the working directory of the console. Importantly, the working directory of an R Markdown code chunk is the folder containing the saved R Markdown file. An R Studio Notebook is an R Markdown file so the working directory of a notebook code chunk is the folder containing the saved notebook file. If an R Markdown file is located within the rmd folder, which is located within the project folder, then the relative file path to “my_file.xlsx” is “../data/my_file.xlsx.” The “..” tells the file OS to move “up” into the parent directory (which is the project folder) and the “data” tells the file OS to move “down” into the data folder. These are put together into a single address using “/.” The beauty of relative paths is that they remain the same – and so do not break one’s script – if the project folder, and all of its contents including the data folder and the rmd folder, is moved to another location on the hard drive (say into a new “Research” folder). By contrast, the absolute file path changes, which breaks any old script.
The three solutions are
- Create a relative path to the file using something like
file_path <- "../data/my_data.xlsx". This should always work but it fails on some computers. For example, if the project folder is on a Windows OS (but not Mac OS) desktop, the assigned relative address doesn’t seem to look in the folder containing the file. - Create a setup chunk that reroutes the working directory to the project folder using the script
# use this in a chuck called "setup" to force the working directory to be
# at the level of the project file.
knitr::opts_knit$set(root.dir = rprojroot::find_rstudio_root_file())For this to work, the chunk has to be named “setup,” that is, the text inside the curly brackets at the top of the chunk should be “r setup.” Then, with this chunk, the relative file path is file_path <- "../data/my_data.xlsx" if “my_data.xlsx” is immediately inside the data folder which is immediately inside the project folder. This should work on any machine, and should work even if a project folder is moved.
- Use the function
here(). The most robust solution seems to be using the functionhere()from the here package. The function works something like this
data_folder <- "data" # path to data that are imported
file_name <- "my_data.xlsx"
file_path <- here(data_folder, file_name) # paste together parts of the address
my_file <- read_excel(file = file_path)here() creates an absolute path, but one that is created on the fly, and will change (or should change) correctly if the project folder is moved on the same machine, to a cloud drive, or to another machine altogether.
3.3 Learning from this chapter
It will be easiest to learn from this chapter by starting with a clean R Markdown document for this chapter. Create a new R Markdown file and save it to the “Rmd” folder of your project. To create and setup the Rmd, follow the steps in Create and setup an R Markdown document (Rmd)
Important: The import method given here will not work properly until the Rmd file is saved! Get in the habit of creating the file, saving it immediately, and saving it often.
Important: The import method will not work properly unless you are working within your R studio project. If you don’t see the name of the project in the upper right of the R Studio toolbar, then you are not in the project. Open the project before moving forward. A good habit is to open R studio by double clicking the project file icon (and not the R Studio icon or the Rmd document that you are working on).
Notes on the setup chunk from Create and setup an R Markdown document (Rmd)
- As you become a better R programmer, be kind to the future you by loading only the packages necessary for the code in the R Markdown file that you are working on. If your default is to load everything, the future you will be confused why something was installed. Again, we’ve disregarded this best practice in this textbook to make sure that chunks don’t fail because of a missing function.
- Be kind to the future you by commenting on why a package is loaded; usually this is a specific function from the package
here <- here::hereis my favorite script ever. What is it doing? One can read this as “assign the function here from the here package to the object here” (this is reading the script right to left). Why do this? It turns out the multiple packages define a function called “here.” If any of these packages are loaded after the here package, thenherefrom here won’t work – it will be replaced byherefrom the more recently loaded package. To make sure thathereuses the function from the here package, I simply reassignherefrom the here package to the object “here” after loading in all packages.
3.4 Working in R
3.4.1 Importing data
3.4.1.1 Importing Excel files
file name: elife-59399-fig1-data1-v2.xlsx
Let’s open the data for Fig. 1H.
Steps
- Highlight and copy the title of the article, which is “Drosophila serotonin 2A receptor signaling coordinates central metabolic processes to modulate aging in response to nutrient choice”
- Create a new folder within the “data” folder. Name the folder the title of the paper by pasting the name from the clipboard. This is the “data from” folder, since it contains the data from the publication with the title of the folder.
- Download the .xlsx file and move it into this folder
The code below uses the function read_excel() from the package readxl. More about the amazing power of this package is the tidyverse page and chapter 11 in the R for Data Science book.
data_from <- "Drosophila serotonin 2A receptor signaling coordinates central metabolic processes to modulate aging in response to nutrient choice"
file_name <- "elife-59399-fig1-data1-v2.xlsx"
file_path <- here(data_folder, data_from, file_name)
exp1h <- read_excel(file_path,
sheet = "H")
exp1h <- clean_names(exp1h) # clean column names
exp1h <- data.table(exp1h) # convert to data.table
# View(exp1h)This book will consistently uses this protocol for importing downloaded Excel files. For any tidy archived data in Excel, a user would simply copy this chunk, paste it into their Rmd, and modify the stuff inside the quotes to import the data. But this is mindless programming. Don’t do this. Understand what each line in the chunk does.
3.4.1.1.1 View the data
Let’s start with the last line, which is commented out
# View(exp1h)The comment (or hashtag) symbol (#) tells R to ignore everything in the line following the symbol. Usually a comment symbol is followed by a brief comment on the code. This comment if mostly for the future you – when you come back after a six month hiatus and wonder what a line or block of code is doing, the comment gives you this information. Sometimes a comment is used in front of R code to keep the R code from running. That is the purpose of the comment symbol here.
View(exp1h) tells R to open a window showing a spreadsheet view of the data.table exp1h. In R studio, this window is opened as a new tab in the Source editor pane (the pane with your Rmd content). To run this code, highlight “View(exp1h)” but not the comment symbol and click the “Run selected line(s)” item in the Run pop-up menu (right side of pane’s tool bar). We don’t include the comment sign in the highlight because this would tell R to ignore everything after it.
We can view the data in exp1h more easily by holding the command key (Mac OS) or the control key (Windows) and clicking the mouse in “exp1h” in any of the lines. Even though I use the mouse click method, I like to have the View(exp1h) at the end of my import chunk to remind me to View the data to make sure everthing imported correctly.
3.4.1.1.2 What does each line in the chunk do?
The first three lines in the chunk create the directory path to the file. This path includes three variables
data_folder– assigned to “data” in the setup chunk. “data” is a folder within the project folder that contains (or will contain) all datasets for this text. The data come from many different published papers, so the data for each publication gets its own folder within “data.”data_from– the name of the “data from” folder within “data” containing the data files. In this text, these folder names will always be the name of the published paper.filename– the name of the file to read. There may be multiple data files within the publication’s data folder.
These are all put together into the absolute path using the function here() from the here package. Take a look at the value of file_path to confirm.
The next three lines (starting with exp1h <-)
read_excelimports the data and assign this to a data.frame namedexp1hclean_namescleans the column names ofexp1hdata.tableconvertsexp1hto a data.table. A data.table is a data.frame with magical properties.
In steps 2 and 3, the functions take the data.frame and process it in some way and then assigned the processed data.frame to an object that has the same name (exp1h). This script can be made slightly more “elegant” using the “pipe” operator %>%.
exp1h <- read_excel(file_path,
sheet = "H") %>%
clean_names() %>%
data.table()This is a single line of code containing three separate operations all piped together. A way to think about this is
- The
read_excelfunction imports the data from the file located at file_path and assigns this data toexp1h. The pipe operator then sends this to - the
clean_namesfunction, which cleans the column names ofexp1h. The pipe operator then sends this to - the
data.tablefunction, which convert the data.frame to a data.table.
A 3rd way to do this is with nested functions.
exp1h <- data.table(clean_names(read_excel(file_path,
sheet = "H"))) # convert to data.tablePrior to the creation of the pipe operator, I nested functions to make code more compact. However, nested functions are often less readable, and I now mostly avoid these and use the pipe operator instead.
Let’s back up to understand the steps, and especially the clean_names step. Here is the first line, which is the line that imports the file.
exp1h <- read_excel(file_path,
sheet = "H")Look at the column names (or column headers in Excel lingo) of the imported data using names or colnames (yes, there are elebenty million ways to do anything in R) (names is very general in that it can be used to return the names of the parts of any list, while colnames is specific to matrix-like objects). Type this into the console, not into your R Markdown chunk:
names(exp1h)## [1] "Diet" "Replicate" "Weight (mg/fly)" "TAG (ug/fly)"
## [5] "Protein (ug/fly)" "TAG/Protein"In general, it is bad practice to include spaces, parentheses, and special characters such as /, -, $, or ^, in the column names of a data frame because these symbols have specific meanings in R functions. The best practice for spaces is to replace the space with an underscore, for example the column header "“Weight (mg/fly)” could be weight_mg_per_fly. Some coders separate words with a period (weight.mg.per.fly). Others mash words together into a single word like this weightmgperfly but this should generally be avoided because the result can be hard to read. Finally, some coders use Caps to separate words like this WeightMgPerFly. This is easier to read than simple concatenation but the underscore is the easiest to read.
The clean_names from the janitor package is a beautiful function to clean the column names of a data frame including replacing spaces with an underscore and stripping parentheses. The default format is snake_case, which replaces all spaces with underscores and changes any uppercase letter with lowercase. Many coders like to work with all lowercase variable names to avoid having to hit the shift key. I am one of these.
Now run the line and look at the column names.
exp1h <- clean_names(exp1h)
names(exp1h)## [1] "diet" "replicate" "weight_mg_fly" "tag_ug_fly"
## [5] "protein_ug_fly" "tag_protein"Finally, run the line
exp1h <- data.table(exp1h)You won’t see any difference if you View the data or peak at the column names. But you’ve transformed the data frame to a data.table and given it magical properties.
Worst Practices – resist the temptation to change the column names in the data file, which reduces reproducibility. Leave original data files original. Always increase reproducibility!
colleague blues – Most researchers live in an Excel world and save data in a way that is efficient for computing stuff in Excel but not efficient for statistical analysis using R or other statistical computing software packages (with the exception of Graphpad Prism). Analyzing data will be much less frustrating if the data are saved in a format that facilitates analysis. Best practices for creating data files
https://www.youtube.com/watch?time_continue=309&v=Ry2xjTBtNFE – An excellent video introduction to best practices for organizing data in a spreadsheet that will subsequently be analyzed by statistics software.
Broman, K. W., & Woo, K. H. (2017). Data organization in spreadsheets (No. e3183v1). https://doi.org/10.7287/peerj.preprints.3183v1 – An excelllent review of best practices for organizing data in a spreadsheet.
3.4.1.1.3 The read_excel function
read_excel is a beautifully flexible function because Excel. Data can be in different sheets and there can be different datasets within a single sheet. And, researchers tend to use Excel like a blackboard in that an Excel sheet often contains calculations such as means, standard deviations and t-tests. When using read_excel it is important to send the function enough information to read the correct data. For the exp1h data, if we simply used
exp1h <- read_excel(file_path) %>%
clean_names() %>%
data.table()without specifying the sheet, read_excel defaults to reading the first sheet (“A”), which is not what we wanted.
We can specify the exact range to important using the range = argument
exp1h <- read_excel(file_path,
sheet = "H",
range = "A1:F49") %>%
clean_names() %>%
data.table()This isn’t necessary for these data because the “H” sheet contains only a matrix of data and not extraneous information and the read_excel function is smart enough to figure this out. For many of the data sets in wet bench experimental biology, the range argument will be crucial because multiple datasets are archived on a single sheet.
We can also specify other arguments. For example, the following code explicitly tells read_excel to use the first row of the data range to be used as the column names and not the first row of data. TRUE is the default argument, so this isn’t necessary for the exp1h data but if the data we want to import doesn’t have column names (and this can be common in archived data sets) then we need to pass the argument “col_names = FALSE.”
exp1h <- read_excel(file_path,
sheet = "H",
range = "A1:F49",
col_names = TRUE) %>%
clean_names() %>%
data.table()3.4.1.1.4 A quick plot of the exp1h data
Just for fun, let’s use the ggboxplot function from the ggpubr package to reproduce something close to Fig. 1H. We could make a plot that looks exactly like Fig. 1H but this would require some of the wrangling outlined below.
ggboxplot(data = exp1h,
x = "diet",
y = "tag_protein",
ylab = "TAG/Protein",
xlab = "",
add = "jitter")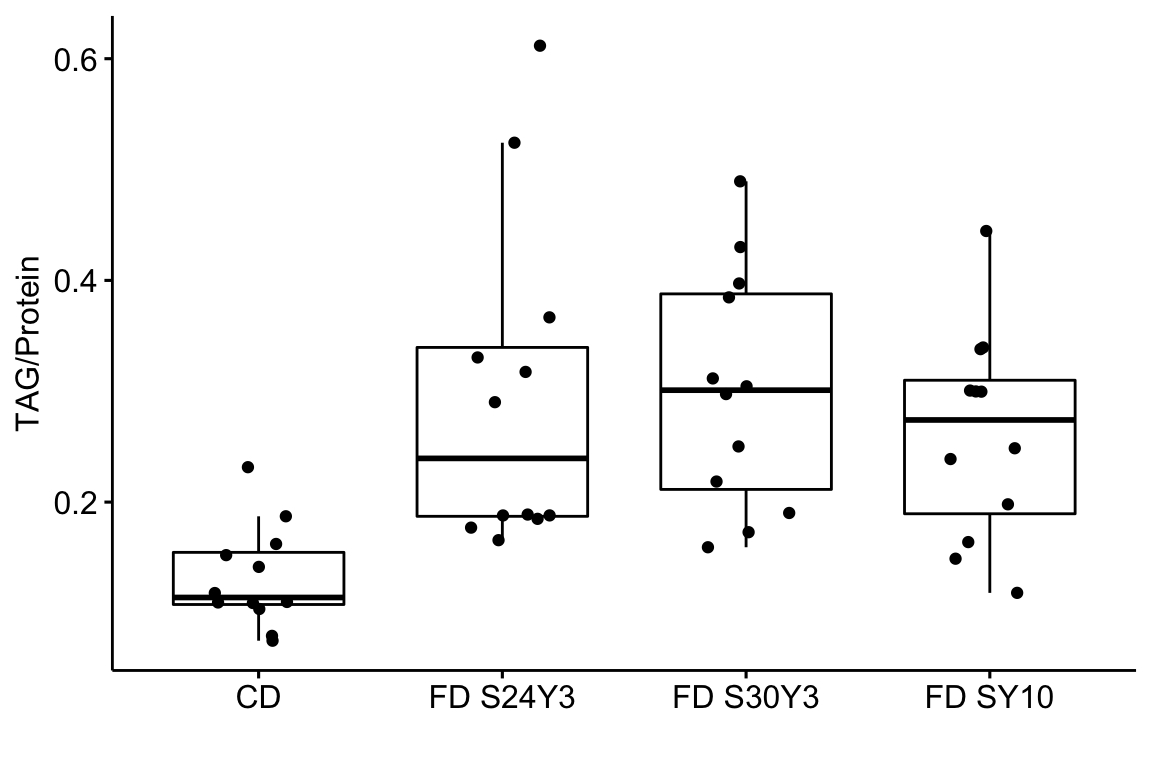
Notes on the code to make this plot
- the names of the columns to use as the x and y axes were passed inside quotes. In some R functions, column names are passed inside quotes and in other R functions, the column names are passed as-is. There is little rhyme or reason for this.
3.4.1.2 Importing text files
Source article: Corrigan, June K., et al. “A big-data approach to understanding metabolic rate and response to obesity in laboratory mice.” Elife 9 (2020): e53560..
file name: mmpc_all_phases.csv
Let’s open the data for Fig. 1.
Steps
- Copy the title of the paper title, which is “A big-data approach to understanding metabolic rate and response to obesity in laboratory mice”
- Create a new folder within “data.” Name the folder the title of the paper by pasting from the clipboard. This is the “data from” folder, since it contains the data from the publication with the title of the folder.
- Click on the link to the file above, highlight all values in the window by clicking inside the window and typing command-a (Mac os) or control-a (Windows) and copy.
- Paste into a an open, blank text document and save it as “mmpc_all_phases.csv.” If saved elsewhere, move this file into the “A big-data approach to understanding metabolic rate and response to obesity in laboratory mice” folder within the “data” folder.
- If you don’t have a dedicated text editor such as BBEdit on MacOS, then open a new R (not Rmd!) document in R studio. This will open as a new tab in the Script Editor pane. Paste the data into the R document window. Save it as “mmpc_all_phases.csv.” R Studio will ask to be sure you want the extension to be .csv and not .R. Yes you are sure. If saved elsewhere, move this file into the “A big-data approach to understanding metabolic rate and response to obesity in laboratory mice” folder within the “data” folder.
A .csv file is a comma-delimited text file, which means that the entries of a row are separated by commas. A text file is readable by any text editor software and most other kinds of software. Datasets that are stored as text files are typically saved as either .csv (where the entries of a row are separated by commas) or .txt (where the entries are separated by tabs). The base R way to read a .csv file is using read.csv. The read.table function is more versatile, as the delimiter can be specified. The function fread() from the data.table package is fast, smart, and flexible. It is smart in the sense that it guesses what the delimter is.
# construct file path
data_from <- "A big-data approach to understanding metabolic rate and response to obesity in laboratory mice"
file_name <- "mmpc_all_phases.csv"
file_path <- here(data_folder, data_from, file_name)
# open file and assign to exp1, then pipe to clean_names
# to change column names to snake_case
exp1 <- fread(file_path) %>%
clean_names()Be sure to read the section on importing Excel files above to understand this code. Here, as with the import of the Excel file, the first three lines create the directory path to the file. There is no need to pipe exp1 to the data.table function because fread automatically opens the data as a data.table. As with the imported Excel file above, this code sends the data object to clean_names to change the column labels to snake_case.
3.4.1.2.1 A quick plot of the exp1 data
Let’s use the ggscatter function from the ggpubr package to reproduce something close to Fig. 1D. We could make a plot that looks exactly like Fig. 1D but this would require some additional plot arguments.
ggscatter(data = exp1[diet == "HF" &
acclimation == TRUE],
x = "total_mass",
y = "ee",
color = "institution",
palette = pal_okabe_ito_4,
add = "reg.line",
ylab = "energy expenditure (kcal/hr)",
xlab = "body mass (g)")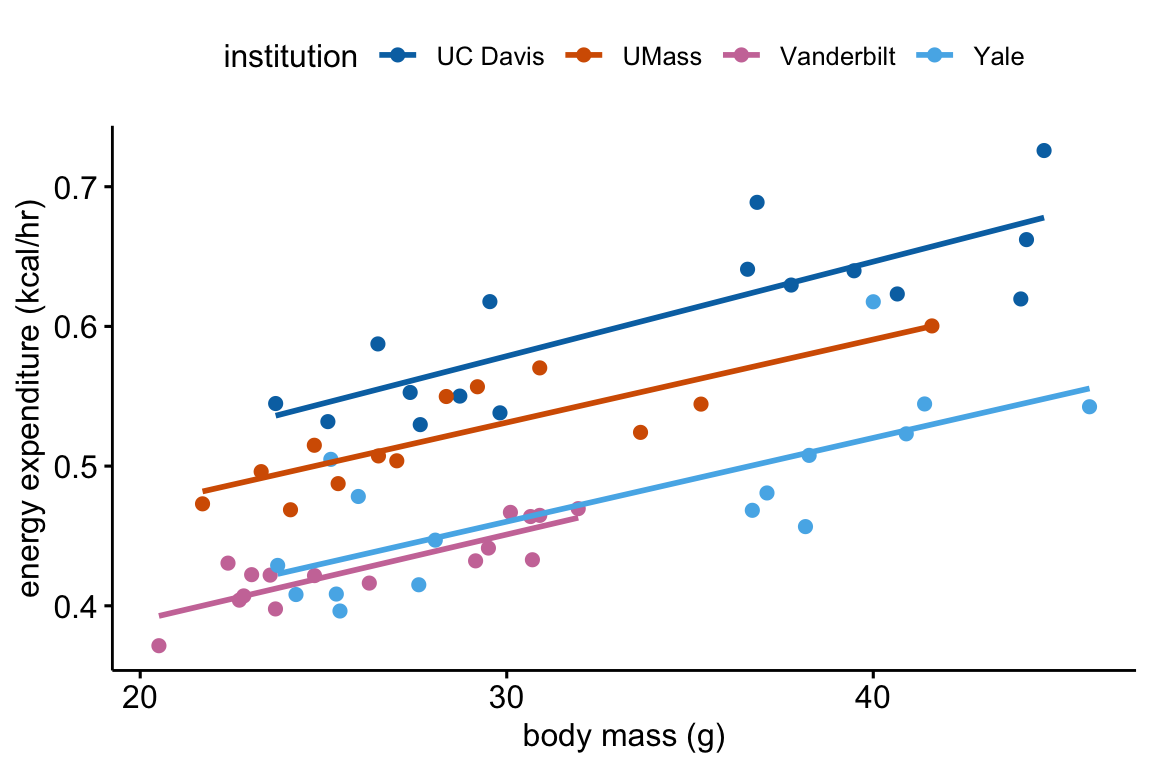
3.4.1.3 Troubleshooting file import
If you get an error that starts with “Error: path does not exist:” then R is not “seeing” your specified file given the path you’ve given it.
- Make sure that you are working within the project by checking the project name on the right side of the R Studio tool bar. If the project is “None” or you are working within a different project, then open the new project.
- Make sure you loaded the package
herein a “setup” chunk and that you have run the setup chunk - Make sure you have assigned
data_folder <- "data"in the setup chunk and have run the chunk. - Make sure your “data” folder is one level inside your project folder. “one level” means it is not buried deeper inside other folders within the project folder.
- Make sure your “data from” folder (the folder with the title of the publication) is one level inside your “data” folder
- Make sure your data file is one level inside the correct “data from” folder.
- Bug alert Make sure you have the name of the “data from …” folder correct in your script. Do not type the name of the folder. Instead, go to the finder and highlight the folder containing the data file, copy the name, return to the R markdown script, type
folder <- ""and then paste the clipboard (the name of the folder) in between the quote marks. - Bug alert Make sure the file name is correct in the script. As with the folder name, I go to the finder and copy the file name and paste it in place. In Windows use ctrl-a instead of ctrl-c to copy the full filename including the extension.
More generally, Humans are very good at understanding misspelld and OdDLy capitalized words but the R language (or any computer language) is very literal. R is case sensitive (some programming languages are not). “Prenatal acoustic communication,” “Prenatal Acoustic Communication,” and “prenatal acoustic communication” are all different values. Spelling AND capitalization have to be perfect, not simply close. Spelling includes spaces. A frequent bug is a file name typed as “Prenatal acoustic communication” when the actual name is “Prenatal acoustic communication.” Can you spot the bug? The original (what we need to copy) has two spaces between “acoustic” and “communication” while the incorrect copy has only one.
Spelling bugs are avoided by simply copying and pasting names of folders, names of files, column names of data frames, and level names of factors, which leads to a general rule of R scripting…
3.5 Data wrangling
Data archived in Excel spreadsheets, at least in wet-bench experimental biology projects, are generally not in a format this is readily analyzed in R, or any statistical software other than perhaps Graphpad Prism. Use these examples as templates for how to import and wrangle Excel-archived data in your project.
3.5.1 Reshaping data – Wide to long
3.5.1.1 Wide to long – Adipsin data
Public source – the Adipsin paper is behind a paywall. A public source of the paper from NIH is available.
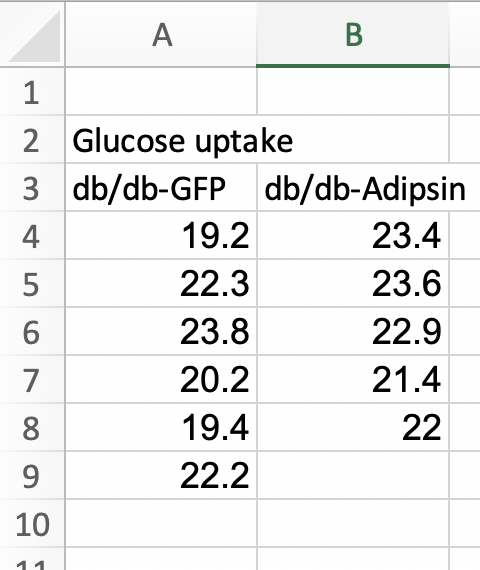
Fig. 1k of the Adipsin paper presents a bar plot of the glucose uptake in response to control (GFP) or adipsin treatment. A screenshot of the Excel-archived data is shown above. The data are in wide format. In wide-format, the values of a single variable (here, this is glucose uptake level) are given in separate columns for each treatment level (group). The values for the GFP group are in Column A and the values for the Adipsin group are in Column B. Wide format is efficient for computations in a spreadsheet, such as computing means and standard deviations of columns of data, and for plotting.
For most statistical analyses of experimental data in R (and most statistics software), all values of a single variable should be in a single column. This is called long format. I’ve manually rearranged the data from the archived spread sheet into long format by stacking each group’s values into a single column, shown in the screen capture below. All values of glucose uptake are in a single column. In long format, there needs to be a way to identify which values belong to which group and this is achieved here with column “treatment.” In adition to the treatment column.
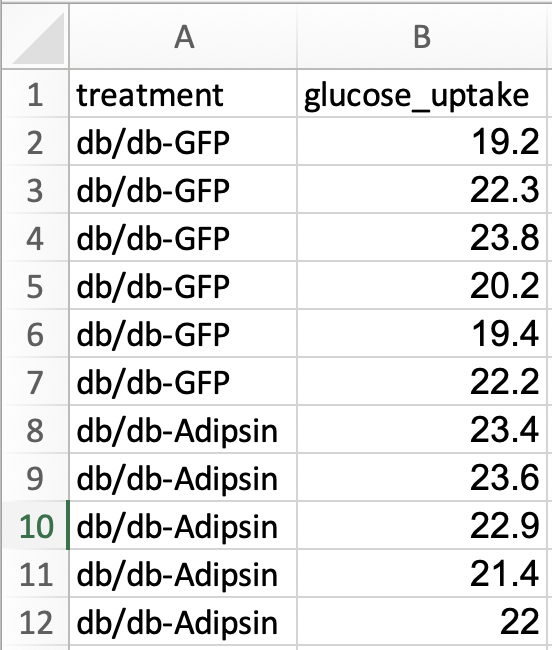
The difference between wide and long also reflects how we think about statistical analysis. When we do a t-test to compare the means of glucose uptake between GFP and Adipsin groups, we might think we have two things: the set of glucose uptake values for the GFP group and the set of values for the Adipsin group. When we fit a linear model, we also have two things, the variable treatment containing treatment level assignment and the variable glucose_uptake containing the glucose uptake values. In wide format, there is nothing to suggest that treatment is a variable.
There are many functions to tidy data from wide to long. melt from the data.table package is especially useful. It is data.table’s version of melt from the reshape2 package.
The major arguments of data.table::melt are
melt(data, id.vars, measure.vars, variable.name, value.name)
melt takes the data in the columns listed in measure.vars and stacks these into a single column named value.name. The names of the columns in measure.vars are the values of the elements in a new column named variable.name. The elements of any column in id.vars are repeated p times, where p is the number of columns that were stacked.
Let’s melt the three different response variables of the adipsin data and merge them into a single data.table. There are several ways to combine data sets including merge and cbind. We’ll compare these later.
file_folder <- "Adipsin preserves beta cells in diabetic mice and associates with protection from type 2 diabetes in humans"
fn <- "41591_2019_610_MOESM3_ESM.xlsx"
file_path <- here(data_folder, file_folder, fn)
treatment_levels <- c("db/db-GFP", "db/db-Adipsin")
# as separate line
fig_1k_wide <- read_excel(file_path,
sheet = "Figure 1k",
range = "A3:B9")
fig_1k_wide <- data.table(fig_1k_wide)
fig_1k <- melt(fig_1k_wide,
measure.vars = treatment_levels,
variable.name = "treatment",
value.name = "glucose_uptake")
# or piped -- which do you prefer?
fig_1k <- read_excel(file_path,
sheet = "Figure 1k",
range = "A3:B9") %>%
data.table() %>%
melt(measure.vars = treatment_levels,
variable.name = "treatment",
value.name = "glucose_uptake")
# View(fig_1k) # highlight without the comment sign and "run selected lines()" to viewA pretty-good-plot using the ggpubr package
# put warning=FALSE into the chunk header to supress the warning
gg <- ggstripchart(x = "treatment",
y = "glucose_uptake",
add = "mean_se",
data = fig_1k)
gg
3.5.1.2 Wide to long – Enteric nervous system data
Let’s import and reshape the data for figure 2d. Look at the excel file and the data in Fig. 2d. There is a single treament with four levels, but the authors have organized the data in each level in separate columns and used the column header as the level name.
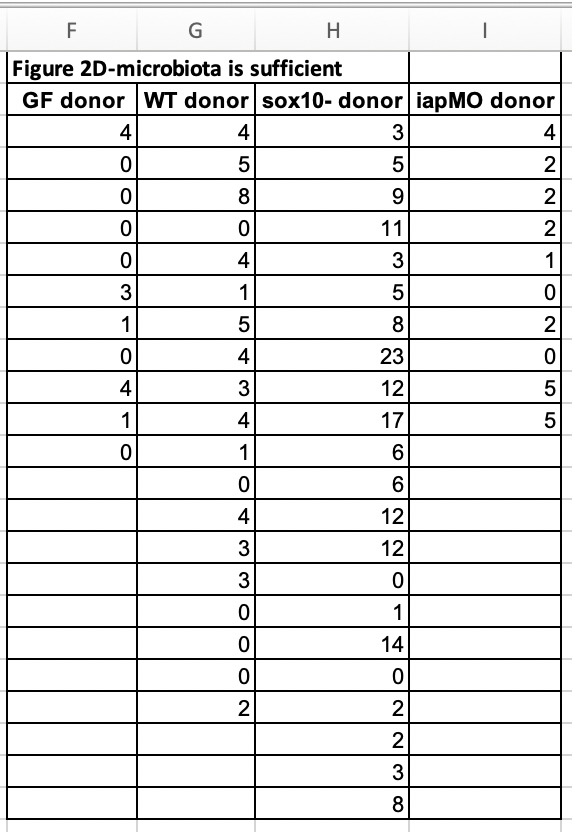
Let’s melt the data from wide to long by stacking the four columns into a single column “neutrophil_count” and adding a treatment column identifying the group.
folder <- "The enteric nervous system promotes intestinal health by constraining microbiota composition"
filename <- "journal.pbio.2000689.s008.xlsx"
file_path <- here(data_folder, folder, filename)
# figure 2D data
sheet_i <- "Figure 2"
range_i <- "F2:I24"
fig_2d_wide <- read_excel(file_path, sheet=sheet_i, range=range_i) %>%
clean_names() %>%
data.table()
# change column names by replacing without "_donor" in each name
# these new column names will become the levels of the treatment factor
new_colnames <- c("gf", "wt", "sox10", "iap_mo")
setnames(fig_2d_wide, old=colnames(fig_2d_wide), new=new_colnames)
# wide to long
fig_2d <- melt(fig_2d_wide,
measure.vars=colnames(fig_2d_wide),
variable.name="treatment",
value.name="neutrophil_count")
# omit empty rows
fig_2d <- na.omit(fig_2d)
# re-order factors
fig_2d[, treatment := factor(treatment,
levels = c("wt", "gf", "sox10", "iap_mo"))]
# View(fig_2d)To learn (instead of just copy and modify), it’s best to do this in steps and not run the whole chunk. At each step, look at the result using View. The script above includes three extra wrangling steps.
Changing column names in fig_2d_wide. The column names in wide format will become the treatment level names of the treatment factor after reshaping. It will be easier down the road if these names are shorter and the "_donor" in each name is redundant. The
setnamesfunction renames the column names.For these data, the number of measures within the different treatments differs and, as a consequence, there are multiple cells with
NAwhich indicates a missing value.View(fig_2d_wide)(this can be typed in the console) to see this. After reshaping to long format (fig_2d), the rows with missing values become empty rows – there is no useful information in them (View this). To see this, re-run the lines of the chunk up to the line “# omit empty rows.” Thena.omitfunction deletes any row with missing values. Here, this deletes these information-less rows. Be very careful withna.omit. You do not want to delete rows of data that contain information you want.For both analysis and plots, we want to compare values to the control level, which is named “wt” for the fig_2d data. That is, we want “wt” to be the reference level. To achieve this, the levels of the factor treatment need to be re-ordered using the
levelsargument. (note, I typically do not add “levels =,” but simply pass the list of levels)
3.5.1.3 Wide to long – bee data
The example above is pretty easy, because the all columns in the original data frame are melted (stacked). Here is an example in which only a subset of columns are stacked. In addition, only a subset of the remaining columns are retained in the long format data frame. The data are from Panel A of supplement Fig. 8 (https://journals.plos.org/plosbiology/article/file?type=supplementary&id=info:doi/10.1371/journal.pbio.2003467.s019){target="_blank"} from
folder <- "Data from Disentangling metabolic functions of bacteria in the honey bee gut"
filename <- "journal.pbio.2003467.s001.xlsx"
# figure 2D data
sheet_i <- "S8 Fig"
range_i <- "A2:H12"
file_path <- here(data_folder, folder, filename)
fig_s8a_wide <- read_excel(file_path,
sheet=sheet_i,
range=range_i) %>%
clean_names() %>%
data.table()
# wide to long
stack_cols <- paste0("replicate", 1:5)
fig_s8a <- melt(fig_s8a_wide,
id.vars = c("media", "time_h"),
measure.vars = stack_cols,
variable.name = "Replicate",
value.name = "OD600") # measure of absorbance at 600nm3.5.1.4 Wide to long – stacking multiple sets of columns
The data are from Fig. 1b
folder <- "GPR109A mediates the effects of hippuric acid on regulating osteoclastogenesis and bone resorption in mice"
file_name <- "42003_2020_1564_MOESM4_ESM.xlsx"
file_path <- here(data_folder, folder, file_name)
fig1b_wide <- read_excel(file_path,
sheet = "Fig. 1b",
range = "C4:R9",
col_names = FALSE) %>%
data.table()
treatment_levels <- c("Wild type", "GPR109A-/-")
treatment_abbrev <- c("wt", "ko")
measures <- c("BV/TV", "Tb.Th", "Tb.Sp", "Tb.N", "BMD", "Cs.Th", "BV", "MA")
new_colnames <- paste(rep(measures, each = 2),
treatment_abbrev,
sep = "_")
setnames(fig1b_wide,
old = colnames(fig1b_wide),
new = new_colnames)| BV/TV_wt | BV/TV_ko | Tb.Th_wt | Tb.Th_ko | Tb.Sp_wt | Tb.Sp_ko | Tb.N_wt | Tb.N_ko | BMD_wt | BMD_ko | Cs.Th_wt | Cs.Th_ko | BV_wt | BV_ko | MA_wt | MA_ko |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5.229493 | 6.697880 | 0.0379685 | 0.0436415 | 0.3383573 | 0.3507201 | 1.377323 | 1.534749 | 0.0927138 | 0.1125594 | 0.1363595 | 0.1445718 | 0.2296399 | 0.2250816 | 0.3832690 | 0.4268379 |
| 5.171787 | 7.271222 | 0.0386800 | 0.0425357 | 0.3579566 | 0.3946835 | 1.337071 | 1.709440 | 0.0930417 | 0.1129723 | 0.1387652 | 0.1430709 | 0.1946119 | 0.2422370 | 0.4216582 | 0.3553190 |
| 4.287585 | 9.873900 | 0.0385307 | 0.0438999 | 0.4401164 | 0.3019478 | 1.112770 | 2.249185 | 0.0782485 | 0.1330846 | 0.1334085 | 0.1588262 | 0.1568608 | 0.3700646 | 0.3620063 | 0.4698913 |
| 4.308528 | 5.557610 | 0.0374626 | 0.0372947 | 0.3576182 | 0.3328132 | 1.150088 | 1.490186 | 0.0841214 | 0.1007773 | 0.1369047 | 0.1288561 | 0.1555844 | 0.2050777 | 0.3661425 | 0.4413361 |
| 5.175202 | 6.673029 | 0.0406120 | 0.0400175 | 0.4541035 | 0.3604716 | 1.274303 | 1.667530 | 0.0921535 | 0.1189364 | 0.1299124 | 0.1438411 | 0.1521829 | 0.2224382 | 0.3578702 | 0.4556137 |
To analyze each response, the two treatment levels for each measure need to be stacked into a single column. This is easy using melt from the data.table package. Add this to your chunk.
fig1b <- melt(fig1b_wide,
measure.vars = list(
c("BV/TV_wt", "BV/TV_ko"),
c("Tb.Th_wt", "Tb.Th_ko"),
c("Tb.Sp_wt", "Tb.Sp_ko"),
c("Tb.N_wt", "Tb.N_ko"),
c("BMD_wt", "BMD_ko"),
c("Cs.Th_wt", "Cs.Th_ko"),
c("BV_wt", "BV_ko"),
c("MA_wt", "MA_ko")),
variable.name = "treatment_id",
value.name = measures)
fig1b[, treatment := ifelse(treatment_id == 1,
treatment_levels[1],
treatment_levels[2])]
fig1b[, treatment := factor(treatment,
levels = treatment_levels)]| treatment_id | BV/TV | Tb.Th | Tb.Sp | Tb.N | BMD | Cs.Th | BV | MA | treatment |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 5.229493 | 0.0379685 | 0.3383573 | 1.377323 | 0.0927138 | 0.1363595 | 0.2296399 | 0.3832690 | Wild type |
| 1 | 5.171787 | 0.0386800 | 0.3579566 | 1.337071 | 0.0930417 | 0.1387652 | 0.1946119 | 0.4216582 | Wild type |
| 1 | 4.287585 | 0.0385307 | 0.4401164 | 1.112770 | 0.0782485 | 0.1334085 | 0.1568608 | 0.3620063 | Wild type |
| 1 | 4.308528 | 0.0374626 | 0.3576182 | 1.150088 | 0.0841214 | 0.1369047 | 0.1555844 | 0.3661425 | Wild type |
| 1 | 5.175202 | 0.0406120 | 0.4541035 | 1.274303 | 0.0921535 | 0.1299124 | 0.1521829 | 0.3578702 | Wild type |
3.5.2 Reshaping data – Transpose (turning the columns into rows)
3.5.2.1 Transpose – PI3K inhibitors data
Source: Suppression of insulin feedback enhances the efficacy of PI3K inhibitors
Figure 3A of this publication is a plot of blood glucose level taken on the same individual mice from four treatment groups over six time periods. Data on a single variable such as blood glucose, taken on the same individual at multiple time points, are known as longitudial data but are often mistakenly called repeated measures data. There are mulitple ways to analyze longitudinal data, some goood, some less good. There are two reasonable ways to archive longitudinal data for analysis in R. The Excel-archived data for Figure 3A is neither. A screen capture of two of the four treatment groups is shown below.

In the archived data the individual mice are in columns. The measure at each time point is in rows. And the treatment group is in blocks. Typical data for analysis in R should have the individual mice in rows and each variable in columns (an exception in experimental biology is omics data, such as RNA expression levels. Many packages with functions to analyze these data have the genes on each row and the individual on each column). The Figure 3A data are turned on its side. We need to transpose the data, or rotate the matrix 90 degrees (make the columns rows and the rows columns) to turn the data into wide format. From this we can create a new data.table with the data in long format.
folder <- "Suppression of insulin feedback enhances the efficacy of PI3K inhibitors"
filename <- "41586_2018_343_MOESM6_ESM.xlsx"
file_path <- here(data_folder, folder, filename)
pi3k_side <- read_excel(file_path,
sheet = "Figure 3A (Blood Glucose)",
range = "A2:U7",
col_names = FALSE) %>%
data.table()
# give columns names as the treatment of each mouse
# verify n=5 per group
treatment_levels <- c("Chow", "Ketogenic", "Metformin", "SGLT2i")
colnames(pi3k_side) <- c("time",
rep(treatment_levels, each = 5))
# transpose
# keep colnames in "side" as values of treatment col in "wide"
# make values of "time" in "side" the colnames in "wide"
pi3k_wide <- transpose(pi3k_side,
keep.names = "treatment",
make.names = "time")
# make a baseline column
pi3k_wide[, glucose_0 := get("0")]
# make-up a mouse id for each mouse
pi3k_wide[, id := paste(treatment, 1:.N, sep = "_"), by = treatment]
# make treatement a factor with "chow" as reference
pi3k_wide[, treatment := factor(treatment, treatment_levels)]
# make a long version
pi3k_long <- melt(pi3k_wide,
id.vars = c("treatment", "id", "glucose_0"),
variable.name = "time",
value.name = "glucose")Notes
- Read the comments on the usage of the
keep.namesandmake.namesarguments oftranspose. These are powerful. - pi3k_wide has column names that are times (in minutes). This presents wrangling problems (column names shouldn’t be numbers. Here it is useful to create the long format data.table with a time column of numbers). For example, the code above creates copies the column “0” into a new column “glucose_0” using
glucose_0 := get("0"). Had the code beenglucose_0 := "0", all values would be the character “0.” Had the code beenglucose_0 := 0, all values would be the number 0.getlooks for the column with the name of whatever is inside the parentheses.
Let’s do a quick plot to examine the data
qplot(x = time,
y = glucose,
data = pi3k_long,
color = treatment) +
geom_line(aes(group = id))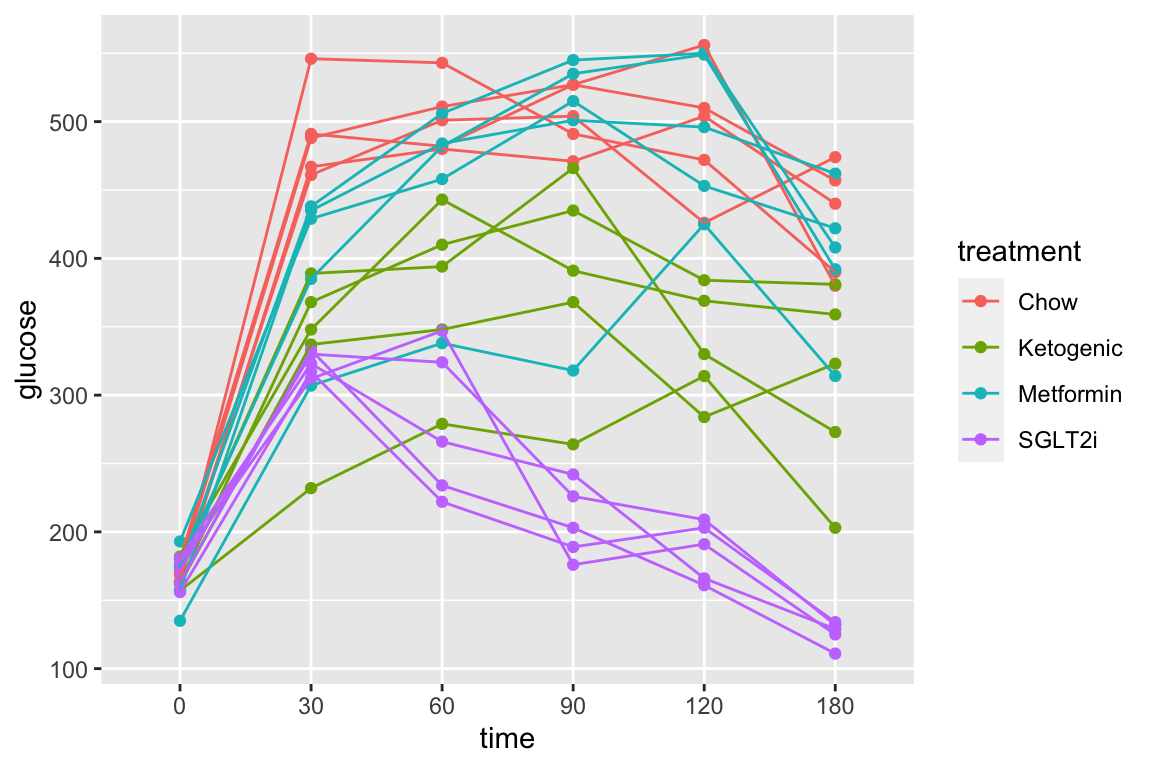
3.5.3 Combining data
The data are from a randomized crossover design where 18 men (9 lean and 9 obese) were measured for multiple metabolic markers at two times: 1) in a post-absorptive state after 12 hours overnight fast, and 2) in a prolonged fasting state after 72 hours of fasting. In addition, at each time point, metabolic markers were measured prior to and after an insulin infusion. Here, we want to reproduce values in Table 2, which are measures of mean blood insulin and metabolite levels after 12 hours and 72 hours fasting in both the lean and obese groups.
A difficulty for the analyst is that the response data are in the “Table 2” sheet but the variable containing the assignment to “lean” or “obese” group is in the “Table 1” sheet. To analyze these response, the two datasets need to be combined into a single data frame. The important consideration when combining data is that like is matched with like. For the fasting dataset, “like” is the subject id, and we have some data for each subject id in Table 1 and other data for the same subject ids in Table 2. This means that we essentially want to glue the columns of table 2 to the columns of table 1 in a way that insures that the correct data for each subject id is on the same row. This is a bit more complicated for these data because Table 1 contains 18 data rows, one for each subject id and Table 2 contains 36 data rows, 2 for each subject id, because each subject has data measured at 12 hours and at 72 hours.
3.5.4 Subsetting data
It is common to see researchers create multiple subsets of data for further processing. This practice should be be discouraged because the same variables will be in multiple data frames and it can be hard to keep track of any processing of variables in the different datasets. Instead, subset the data at the level of analysis.
There are many ways to subset data in R. Experienced users tend to divide up into those using base R, those using the tidyverse packages, or those using data.table. Learn one well. This book uses data.table. Before outlining usage in data.table, let’s back up a bit and review different indexing systems.
- In Excel, rows are specified (or “indexed”) by numbers and columns by letters. Every cell has an address, for example C2 is the cell in the 2nd row and 3rd column. Notice that in Excel, the column part of the address comes before the row part.
- In statistics, it is extremely common to use a system where is the value of the element in the ith row and jth column of the matrix X. Notice that in this notatin, the row index (i) comes before the column index (j).
- In programming languages, including R, it is extremely common to use a system where my_data[i, j] is the value of the element in the ith row and jth column of the matrix-like object named “my_data” (such as a data frame in R).
- data.table explicitly refers to the row index and column index as i and j.
3.5.4.1 Specifying a subset of rows (“observations” or “cases”)
A subset of rows is specified using either a list of row numbers or
In a data.table, a subset of rows is specified using either a list of row numbers or a combination of comparison operators (==, !=, >, <, >=, <=, %in%) and Boolean logic operators (&, |, ! – these are “and,” “or,” “not”) as i.
Let’s use the pi3k_long data from above to explore this. First, the plot of plasma glucose for all individuals in each treatment group across all time points.
qplot(x = time,
y = glucose,
data = pi3k_long,
color = treatment) +
geom_line(aes(group = id))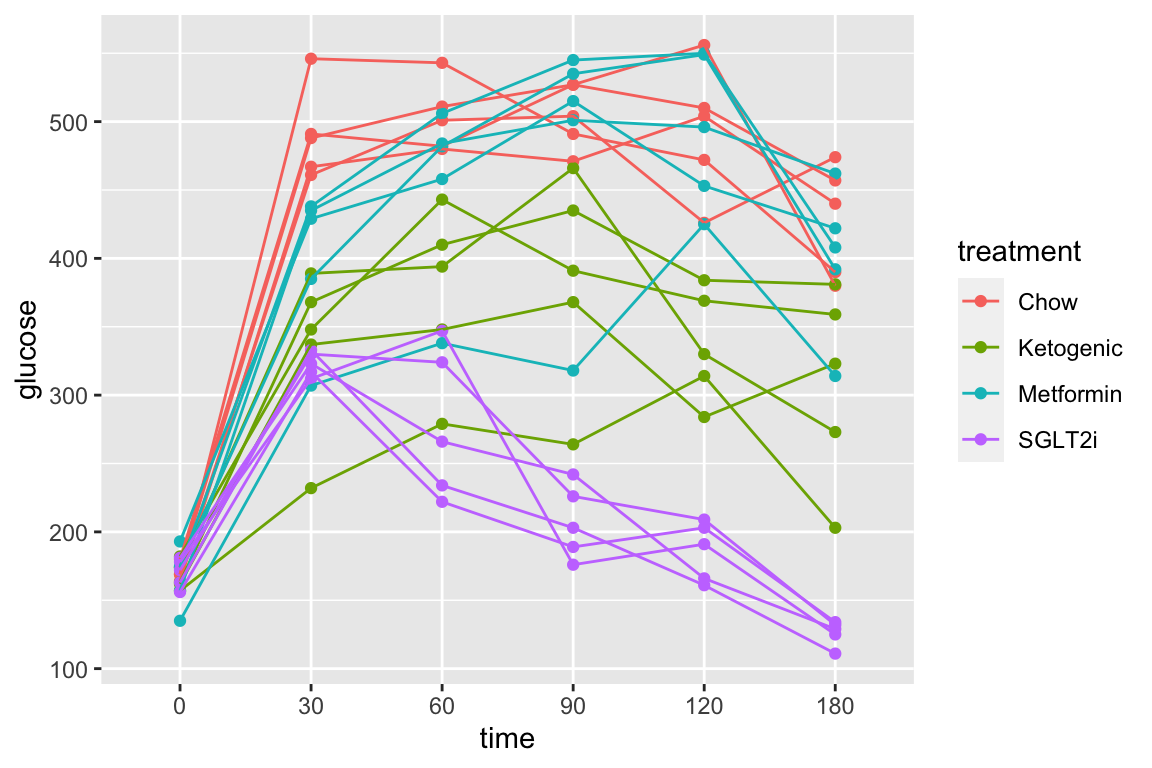
pi3k_long[treatment == "Chow",]) is the subset of rows in which entries in the column “treatment” take the value “Chow” using the “is equal” (“==”) operator
qplot(x = time,
y = glucose,
data = pi3k_long[treatment == "Chow",],
color = treatment) +
geom_line(aes(group = id))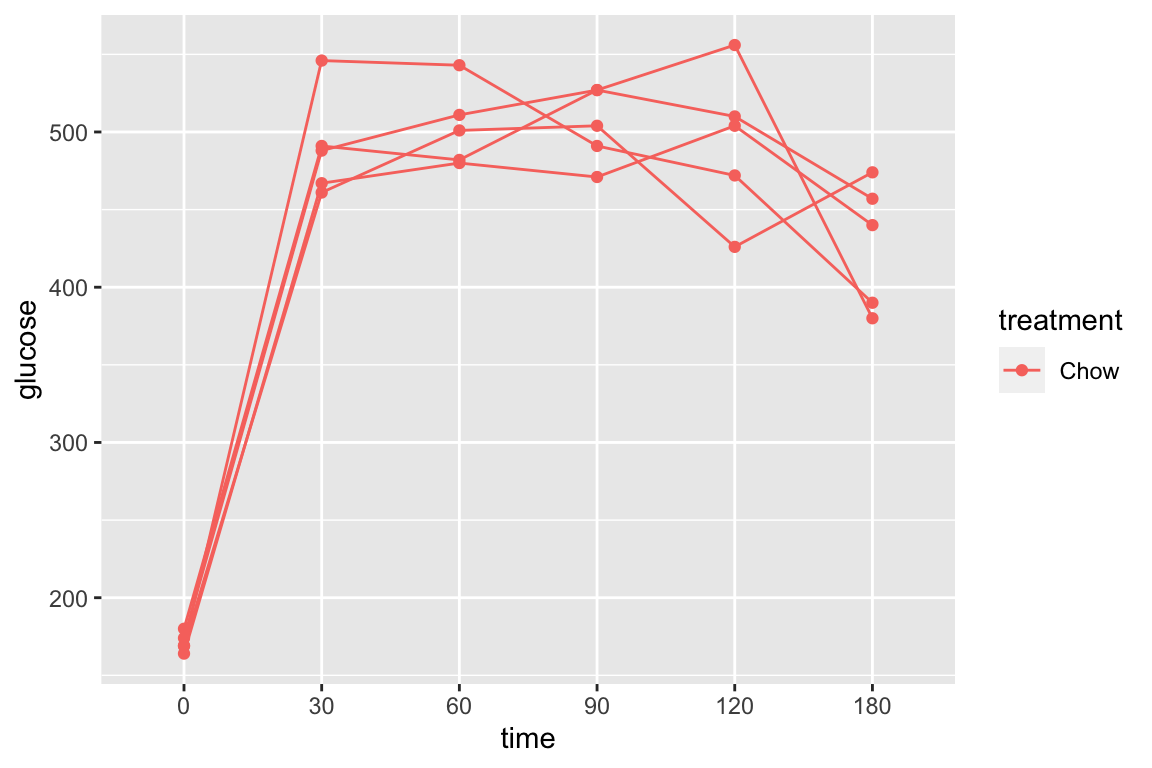
And the subset of rows in which entries in the column “treatment” take any value but “Chow” using the “not equal” operator (“!=”).
qplot(x = time,
y = glucose,
data = pi3k_long[treatment != "Chow",],
color = treatment) +
geom_line(aes(group = id))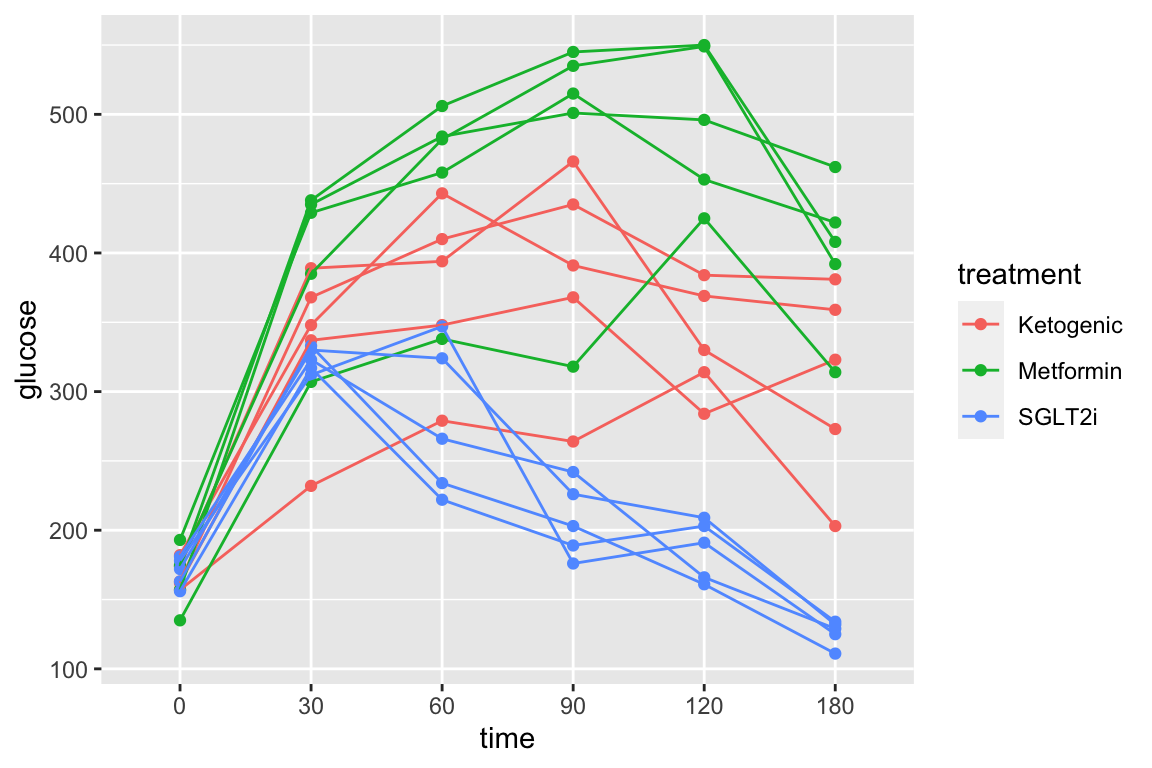
The subset of rows in which entries in the column “treatment” take either the value “Chow” or the value “SGLT2i” by combining two “is equal” (“==”) operators using the OR (“|”) boolean operator
qplot(x = time,
y = glucose,
data = pi3k_long[treatment == "Chow" | treatment == "SGLT2i",],
color = treatment) +
geom_line(aes(group = id))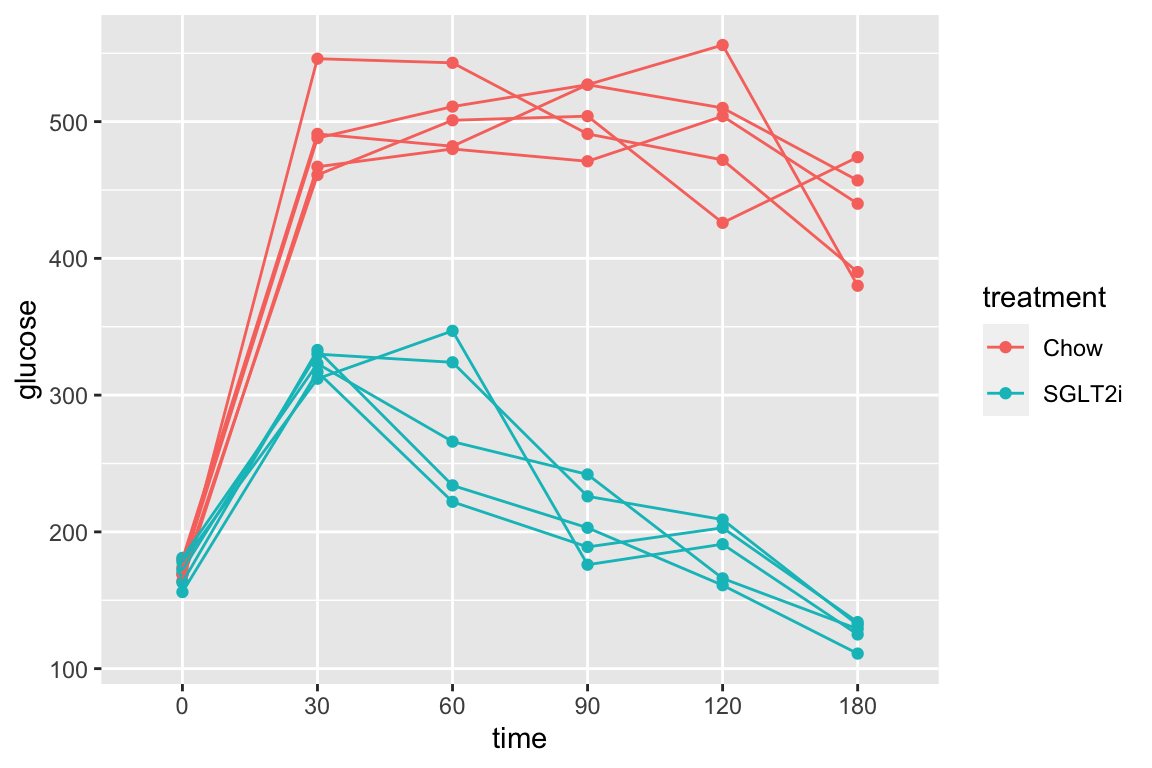
The subset of rows in which entries in the column “time” take either the value “30” or the value “60” using the “in a list” operator (%in%). The values in the “time” column look like integers but are actually treatment levels (which act like string or character variables).
qplot(x = time,
y = glucose,
data = pi3k_long[time %in% c("30", "60"),],
color = treatment) +
geom_line(aes(group = id))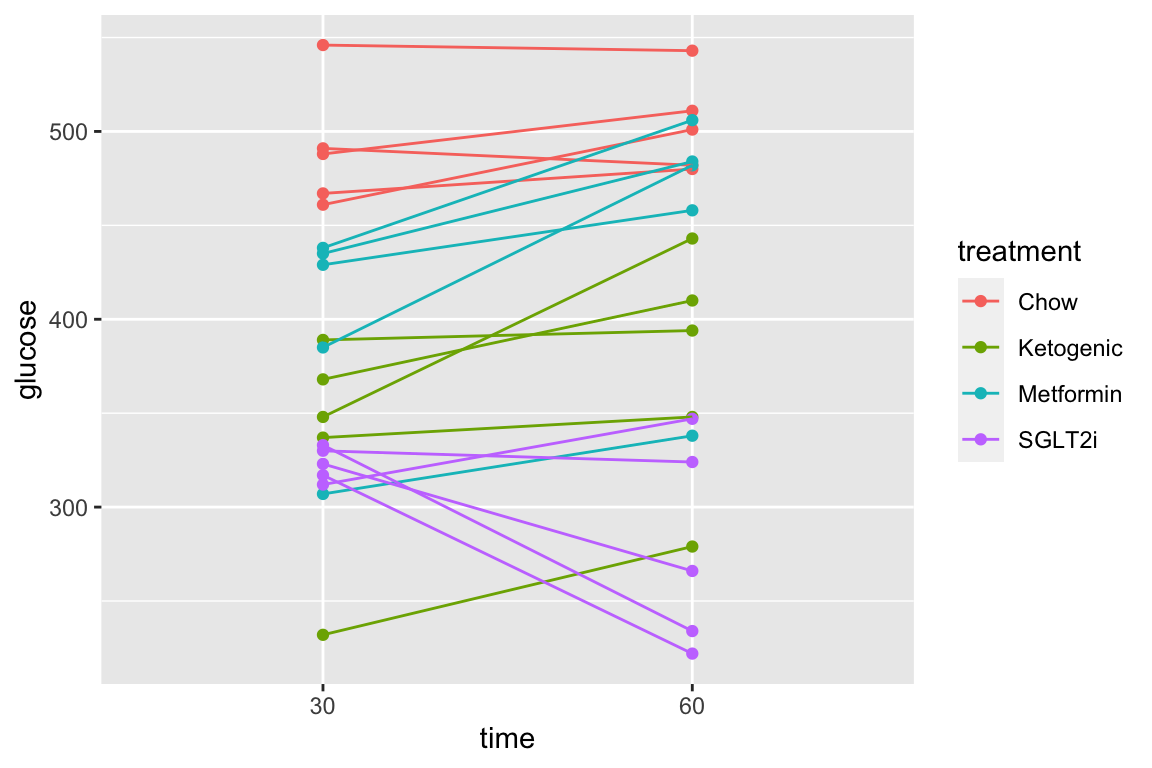
The subset of rows in which entries in the column “time_c” are less than or equal to 60 using the “less than or equal to” operator AND the value in the treatment column is in the list (“Chow,” “SGLT2i”). The two comparisons are combined with the AND (“&”) Boolean operator.
pi3k_long[, time_c := as.numeric(as.character(time))]
qplot(x = time,
y = glucose,
data = pi3k_long[time_c <= 30 & treatment %in% c("Chow", "SGLT2i"),],
color = treatment) +
geom_line(aes(group = id))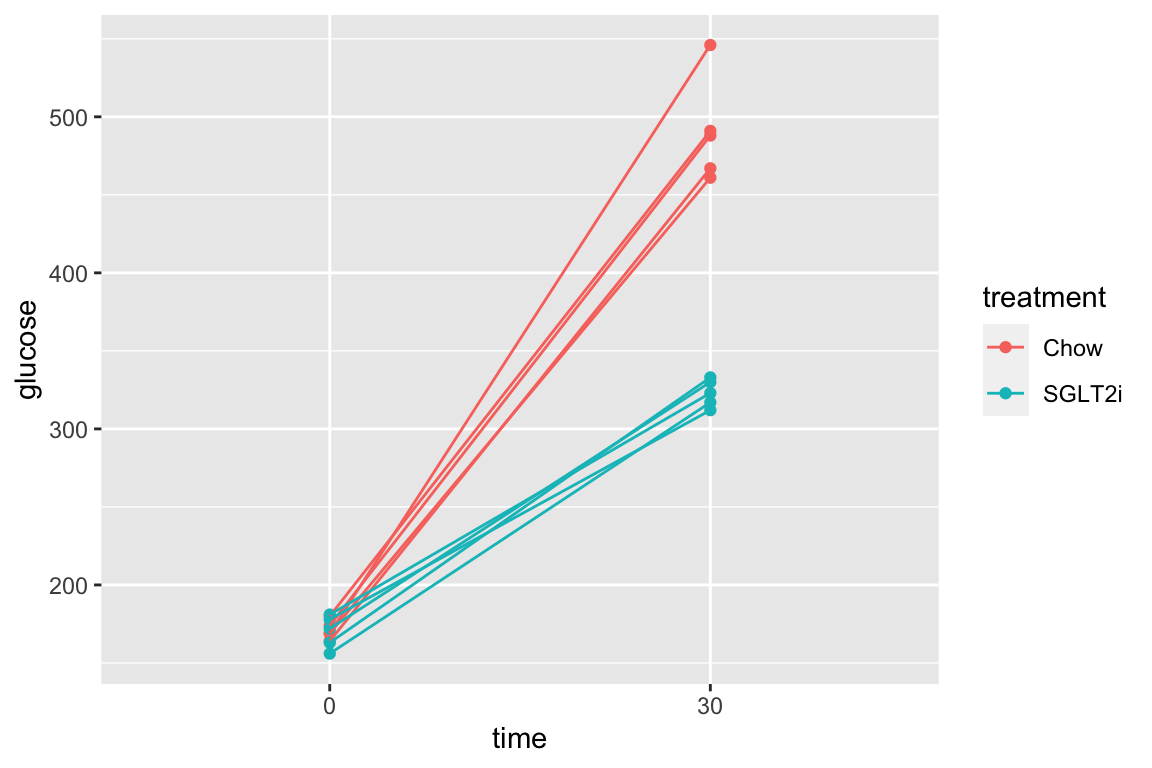
The same result as above but using different operators. I would describe this as, the subset of rows in which entries in the column “time_c” are less than or equal to 60 using the “less than or equal to” operator AND the value in the treatment column is either “Chow” OR “SGLT2i.” The two comparisons are combined with the AND (“&”) Boolean operator. The order of operations is determined by the parentheses, as with all algebra.
pi3k_long[, time_c := as.numeric(as.character(time))]
qplot(x = time,
y = glucose,
data = pi3k_long[time_c <= 30 & (treatment == "Chow" | treatment == "SGLT2i"),],
color = treatment) +
geom_line(aes(group = id))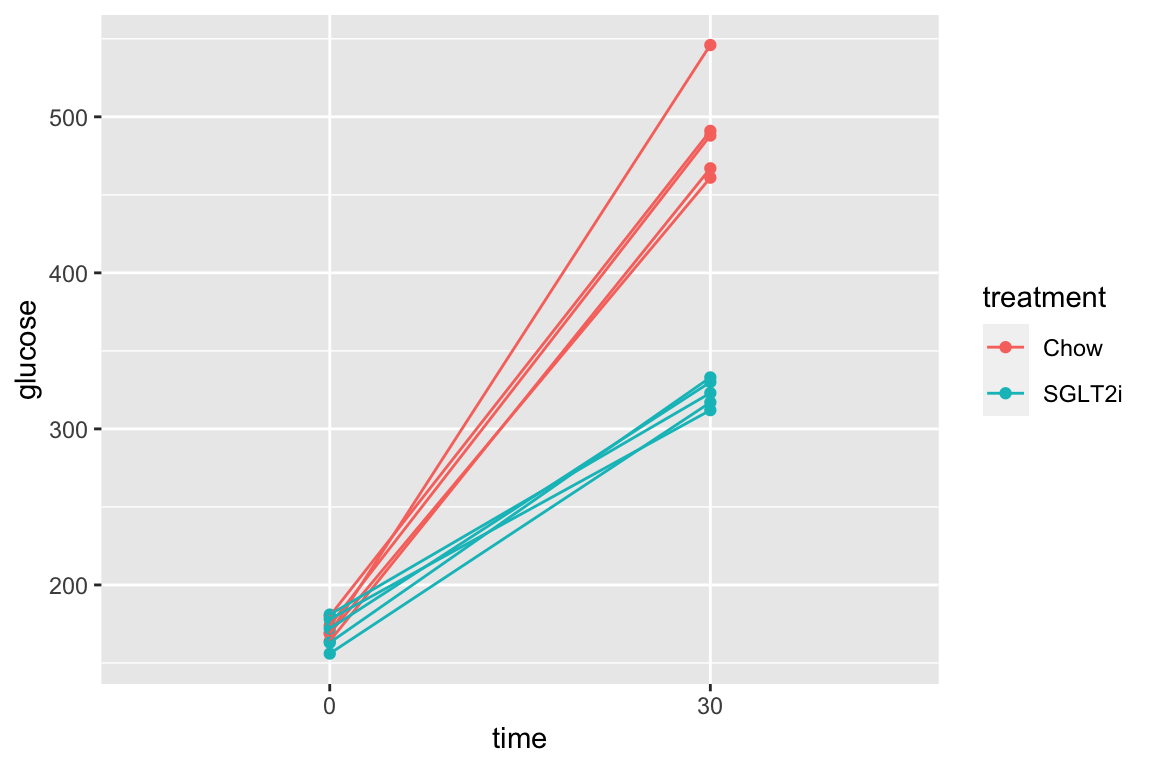
3.5.5 Wrangling columns
3.5.5.3 Converting a single column with all combinations of a 2 x 2 factorial experiment into two columns, each containing the two levels of a factor
3.5.5.3.1 Example 1 (tstrspl)
The example data are analyzed in the chapter Linear models with two categorical – Factorial linear models (“two-way ANOVA”)
Article source: TLR9 and beclin 1 crosstalk regulates muscle AMPK activation in exercise
The data are from Figure 2j.
data_from <- "TLR9 and beclin 1 crosstalk regulates muscle AMPK activation in exercise"
file_name <- "41586_2020_1992_MOESM4_ESM.xlsx"
file_path <- here(data_folder, data_from, file_name)
treatment_levels <- c("WT Resting",
"WT Active",
"Tlr9-/- Resting",
"Tlr9-/- Active")
exp2j_wide <- read_excel(file_path,
sheet = "2j",
range = "A5:D13",
col_names = TRUE) %>%
data.table()
colnames(exp2j_wide) <- treatment_levels
exp2j <- melt(exp2j_wide,
measure.vars = treatment_levels,
variable.name = "treatment",
value.name = "glucose_uptake") %>%
na.omit() # danger!
exp2j[, c("genotype", "stimulation") := tstrsplit(treatment,
" ",
fixed = TRUE)]
genotype_levels <- c("WT", "Tlr9-/-")
stimulation_levels <- c("Resting", "Active")
exp2j[, genotype := factor(genotype,
levels = genotype_levels)]
exp2j[, stimulation := factor(stimulation,
levels = stimulation_levels)]
# View(exp2j)- Melting the wide data creates a column containing the column names of the wide data. The column type is character (often called “string” because each the variable is a string of characters). We want to split the string at the space, and put the first part into one new column and the second part into a second new column.
- The
tstrsplit()function from the data.table package does this split for us. The first argument is the name of the column that contains the strings that we want to split. The second argument is the character that we want to split on.c("genotype", "stimulation")before:=sets the names of the new columns containing. This is a really elegant solution. - I replaced the original column names of initial import for several reasons:
- “Electrical Stimulation” is too long and will make the coefficient names unwieldy. This could be shortened to “Stimulation,” but…
- I don’t want a factor name to include a level with the same name. I like the factor name , so I I renamed the level “Electrical Stimulation” to “Active.”
- We are splitting the column names using the space character " " and two of the original column names have two spaces, the 2nd inside what should be a single level (“Electrical Stimulation”)
- The read_excel function removed a space in the last column name, which is read as “Tlr9-/-Electrical Stimulation.”
Here is a peek at the data prior to melting wide to long
| WT Resting | WT Active | Tlr9-/- Resting | Tlr9-/- Active |
|---|---|---|---|
| 5.437741 | 9.511914 | 7.969706 | 7.793486 |
| 6.026892 | 9.901527 | 9.660112 | 9.561649 |
| 7.731616 | 13.038920 | 6.709424 | 8.055529 |
| 6.285710 | 9.665391 | 5.259744 | 7.739374 |
| 7.343797 | 8.590693 | 8.244721 | 10.312190 |
And a peek of the first three and last three rows after the melt.
| treatment | glucose_uptake | genotype | stimulation |
|---|---|---|---|
| WT Resting | 5.437741 | WT | Resting |
| WT Resting | 6.026892 | WT | Resting |
| WT Resting | 7.731616 | WT | Resting |
| Tlr9-/- Active | 10.312190 | Tlr9-/- | Active |
| Tlr9-/- Active | 7.943574 | Tlr9-/- | Active |
| Tlr9-/- Active | 9.292673 | Tlr9-/- | Active |
3.5.5.3.2 Example 2
Source: Tauriello, D., Palomo-Ponce, S., Stork, D. et al. TGFβ drives immune evasion in genetically reconstituted colon cancer metastasis. Nature 554, 538–543 doi:10.1038/nature25492
filename: “41586_2018_BFnature25492_MOESM10_ESM.xlsx”
sheet: “Fig. 4h-tumours”
The analysis of the data in Fig. 4h specifies a single variable “Treatment” with four levels (or groups): “Con,” “Gal,” “aPD-L1,” and “Gal+aPD-L1.” These levels indicate that the design is actually factorial with two factors, each with two levels. The first factor has levels “no Gal” and “Gal.” The second factor has levels “no aPD-L1,” “aPD-L1.” The single column Treatment “flattens” the 2 X 2 factorial design to a 4 x 1 design. In general, we would want to analyze an experiment like this as factorial model, because this allows us to make inferences about the interaction effect between the two factors. For these inferences, we need a standard error, or a confidence interval, or a p-value of the estimate, which we can easily get from the factorial model. In order to analyze the data with a factorial model, we need to create two new columns – one column is the factor variable containing the two levels of Gal and one column is the factor variable containing the two levels of aPD-L1.
gal_levels <- c("no Gal", "Gal")
tumor[, gal := ifelse(treatment == "Gal" | treatment == "Gal+aPD-L1",
gal_levels[2],
gal_levels[1])]
apd_levels <- c("no aPD-L1", "aPD-L1")
tumor[, apdl1 := ifelse(treatment == "aPD-L1" | treatment == "Gal+aPD-L1",
apd_levels[2],
apd_levels[1])]
# re-order factor levels
tumor[, gal:=factor(gal, gal_levels)]
tumor[, apdl1:=factor(apdl1, apd_levels)]A way to check the results to make sure that our conversion is correct is to compute the sample size for the 2 x 2 combinations, but include the original treatment column in the by list.
tumor[!is.na(num_positive_per_mm), .(N=.N), by=.(treatment, gal, apdl1)]## treatment gal apdl1 N
## 1: Con no Gal no aPD-L1 124
## 2: Gal Gal no aPD-L1 89
## 3: aPD-L1 no Gal aPD-L1 101
## 4: Gal+aPD-L1 Gal aPD-L1 58That looks good.
Bug alert If you break Rule #1, and type in the treatment level “Gal+aPD-L1” as “Gal + aPD-L1,” then you will get new columns containing junk.
## treatment gal apdl1 N
## 1: Con no Gal no aPD-L1 124
## 2: Gal Gal no aPD-L1 89
## 3: aPD-L1 no Gal aPD-L1 101
## 4: Gal+aPD-L1 no Gal no aPD-L1 58Remember Rule #1. Always copy and paste any text that will be inserted into quotes. This is easily done here by typing unique(tumor$treatment) into the console. This function returns the unique values of the column “treatment” of the data.table “tumor.”
unique(tumor$treatment) [1] “Con” “Gal” “aPD-L1” “Gal+aPD-L1”
Now, copy the name of a level and paste into your code. Repeat until done.
3.5.6 Missing data
Supplement Figure 1F of this paper shows weight as a function of age class and genotype for the whole body and 8 organs. There are some missing weights in the Excel-archived data. These missing data are designated with a minus “-” sign. To import these data in correctly, use the na = argument in the read_excel function.
file_folder <- "Deletion of Cdkn1b in ACI rats leads to increased proliferation and pregnancy-associated changes in the mammary gland due to perturbed systemic endocrine environment"
file_name <- "journal.pgen.1008002.s008.xlsx"
file_path <- here(data_folder, file_folder, file_name)
fig_s1f <- read_excel(file_path,
sheet = "all weights",
range = "A2:K57",
na = "-",
col_names = TRUE) %>%
clean_names() %>%
data.table()
fig_s1f[, genotype := factor(genotype, c("+/+", "-/-"))]
fig_s1f[, age_class := ifelse(age_at_sac_wks <= 6.0, "4-6", "8+")]
# View(fig_s1f)Notes
- In R, a value of “NA” represents missing.
- The default value for
na =is an empty (or blank) cell (not a space but a cell that is empty). na =accepts a list of strings, for examplena = c("", "-99", "--")that will all be read as na.
3.5.6.1 Handling missing data
3.5.6.1.1 Many base R functions used for summary measures require NA handling
mean(fig_s1f[, ovary]) # returns "NA"## [1] NAmean(fig_s1f[, ovary], na.rm = TRUE) # returns the mean## [1] 0.2489524sd(fig_s1f[, ovary]) # returns "NA"## [1] NAsd(fig_s1f[, ovary], na.rm = TRUE) # returns the mean## [1] 0.151694sum(fig_s1f[, ovary]) # returns "NA"## [1] NAsum(fig_s1f[, ovary], na.rm = TRUE) # returns the mean## [1] 10.456There are many ways to get the sample size for a particular variable. Be careful if using length() which counts NA as part of the vector of values.
3.5.6.1.2 The !is.na function is useful
length(fig_s1f[, ovary])## [1] 55length(fig_s1f[!is.na(ovary), ovary])## [1] 42Notes
!is.na(ovary)is taking the subset of rows of fig_s1f for which the value of “ovary” is not NA (!is.na is read “not is.na”)
This is especially useful if you are creating your own code uses counts. Here I create a table of means, standard error of the mean, and 95% CIs of the mean for each genotype group. But first, this script generates the wrong N for each group (since there are missing values), although the mean and SD are correct.
fig_s1f[, .(mean = mean(spleen, na.rm = TRUE),
n = .N,
sd = sd(spleen, na.rm = TRUE)),
by = genotype]## genotype mean n sd
## 1: -/- 0.5801333 21 0.13680480
## 2: +/+ 0.2956667 34 0.04460855To compute the correct n, which will be necessary for computing the SE and the CI, use !is.na
spleen_summary <- fig_s1f[!is.na(spleen), .(mean = mean(spleen),
n = .N,
sd = sd(spleen)),
by = genotype]
spleen_summary[, se := sd/sqrt(n)]
spleen_summary[, lower := mean + se*qt(.025, (n-1))]
spleen_summary[, upper := mean + se*qt(.975, (n-1))]
spleen_summary## genotype mean n sd se lower upper
## 1: -/- 0.5801333 15 0.13680480 0.03532285 0.5043734 0.6558933
## 2: +/+ 0.2956667 27 0.04460855 0.00858492 0.2780201 0.31331323.5.6.1.3 ggplot functions automatically handle missing values
with a useful warning.
qplot(x = body_wt_g_sac,
y = spleen,
color = genotype,
data = fig_s1f)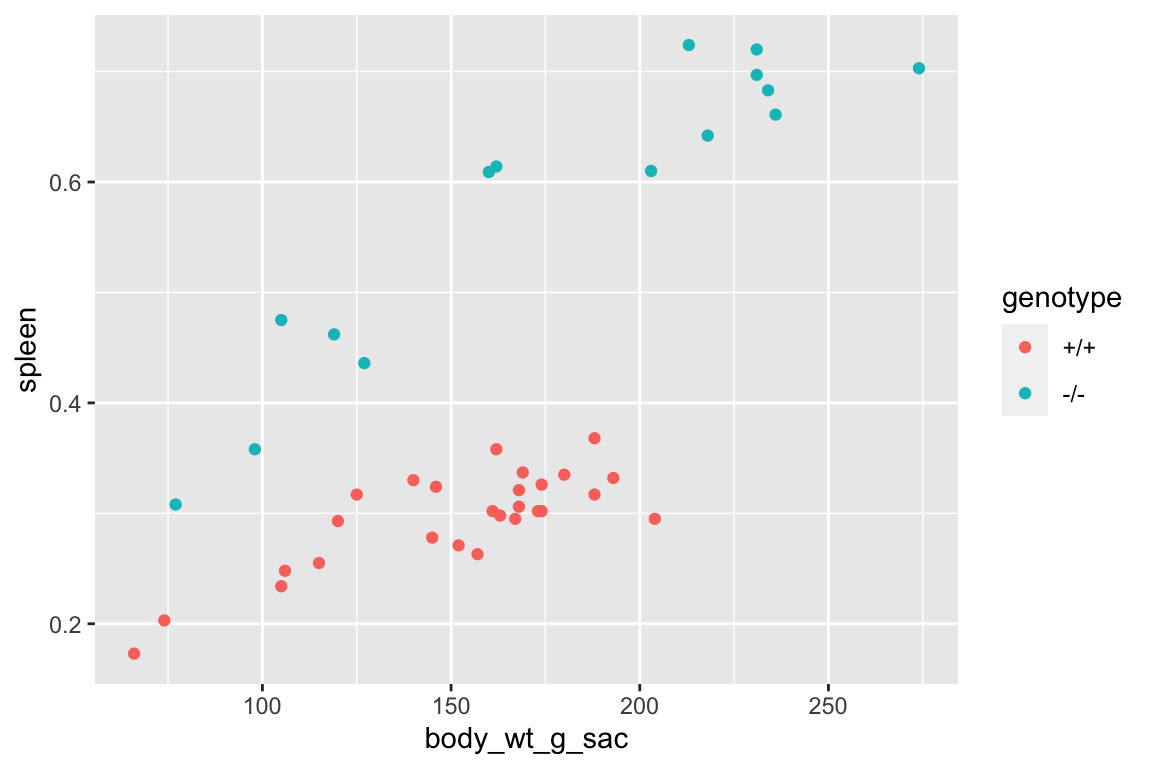
3.5.6.1.4 Regression model functions (lm, glm, gls, etc.) handle missing values by default
Missing data in regression model functions such as lm are handled using the argument na.action = and the default is “na.omit,” which omits any rows that contain a missing value in one or more of the model variables (it includes rows if these contain missing values only in the columns not included in the model). It’s as if the user took the subset of data including only the columns containing the model variables and then deleted any row with missing values.
Here is the coefficient table of the fit model object that did not explictly tell the lm function how to handle missing data.
m1 <- lm(spleen ~ body_wt_g_sac + genotype,
data = fig_s1f)
coef(summary(m1))## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.04238009 0.0242993900 1.744081 8.902319e-02
## body_wt_g_sac 0.00167493 0.0001506493 11.118067 1.170042e-13
## genotype-/- 0.23760586 0.0147600545 16.097898 8.072069e-19Here is the coefficient table of the fit model object that did explicitly tell lm how to handle missing data, using the argument na.action = "na.exclude". These coefficient tables are the same.
m2 <- lm(spleen ~ body_wt_g_sac + genotype,
data = fig_s1f,
na.action = "na.exclude")
coef(summary(m2))## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.04238009 0.0242993900 1.744081 8.902319e-02
## body_wt_g_sac 0.00167493 0.0001506493 11.118067 1.170042e-13
## genotype-/- 0.23760586 0.0147600545 16.097898 8.072069e-193.5.6.2 But…beware of fitted, predicted, or residual values from regression model functions unless you’ve explictly told the function how to handle missing values
Use na.action = "na.exclude" if you want to add the fitted (or predicted) values or residuals as new columns in the original data object (fig_sf1). Compare the length of the fitted values vector from models m1 (using the default “na.omit”) and m2 (using the “na.exclude”).
length(fitted(m1))## [1] 42length(fitted(m2))## [1] 55There are 55 observations (rows in the data) but only 42 complete rows with no missing values. The vector of fitted values from m1 has 42 fitted values. The vector of fitted values from m2 has 55 elements, the 42 fitted values plus 13 NA elements.
This is important if we want to do something like add the fitted values (or residuals, or some function of these) to the original data object (fig_sf1). Here I compute the spleen weights adjusted to the mean body weight of the control (“+/+”) group using the residuals from m1 and m2.
mean_x_control <- mean(fig_s1f[genotype == "+/+", body_wt_g_sac])
b <- coef(m1)
fig_s1f[, spleen_adj_m1 := b[1] +
b[2]*mean_x_control +
b[3]*(as.integer(genotype)-1 +
residuals(m1))]
fig_s1f[, spleen_adj_m2 := b[1] +
b[2]*mean_x_control +
b[3]*(as.integer(genotype)-1 +
residuals(m2))]
# View(fig_s1f)The computation of “spleen_adj_m1” returns a warning that the values of residuals(m1) were recycled (the first 42 elements of the new column were filled with the 42 residuals and the last 13 elements of the new column were filled with the first 13 residuals) – after the first row of missing data, all of these computed adjusted values are wrong. Using residuals(m2), the adjusted values are matched to the correct row and the rows with missing variables do not have an adjusted value (because there is no residual to compute this).
3.6 Saving data
For many projects, it is uncommon to save data. I might save simulated data if it takes a long time (tens of minutes to hours or even days) to generate these and I simply want to work with the simulated data in the future and not have to regenerate it. Or I might save wrangled data if it takes a long time to import and wrangle and I want to analyze the wrangled data in the future and not have to re-import and re-wrangle it.
If the data will only be used in this or future R projects, the data can be saved as an R object using saveRDS()
data_from <- "Drosophila serotonin 2A receptor signaling coordinates central metabolic processes to modulate aging in response to nutrient choice"
outfile_name <- "elife-59399-fig1h.Rds"
save_file_path <- here(data_folder, data_from, outfile_name)
saveRDS(object = exp1h, file = save_file_path)
# to read this use
exp1h <- readRDS(save_file_path)Reading a large .Rds file is very fast compared to reading the same data stored as a text file. However, if the data need to be imported into some other software, such as a spreadsheet, then save the data as a text file.
# save the data to correct data_from folder
data_from <- "Drosophila serotonin 2A receptor signaling coordinates central metabolic processes to modulate aging in response to nutrient choice"
# tab delimited
outfile_name <- "elife-59399-fig1h.txt"
save_file_path <- here(data_folder, data_from, outfile_name)
write.table(exp1h, save_file_path, sep = "\t", quote = FALSE)
# comma delimited
outfile_name <- "elife-59399-fig1h.csv"
save_file_path <- here(data_folder, data_from, outfile_name)
write.table(exp1h, save_file_path, sep = ",", quote = FALSE)Look at your project directory to make sure the file is where it should be! We used write.table() to create a tab-delimited text file using sep = "\t" to specify tabs to separate the row elements. “ is the standard character string for a tab. Check in your data_from folder (with the name”Drosophila serotonin 2A receptor signaling coordinates central metabolic processes to modulate aging in response to nutrient choice") and open the file in a text editor.
3.7 Exercises
- Import and pretty-good-plot the data for Figure 2i of the Adipsin paper. You will need to download and archive the Excel file for “Figure 2.” Store this within the “Adipsin preserves beta cells…” folder.
- The data are the percent of cells staining for NKX6.1, which is a transcription factor protein that regulates beta cell development in the pancreas. Beta cells sense glucose levels in the blood and secrete insulin. Disruption of the insulin signaling system results in Diabetes mellitus.
- The data are in wide format, with each treatment group in a separate column. The data need to be melted into long format with a new column called “treatment.”
- This will give you a pretty good plot of the data (if the data object is named “adipsin_fig2i”)
ggstripchart(data = adipsin_fig2i,
x = "treatment",
y = "nkx6_1",
add = "mean_se")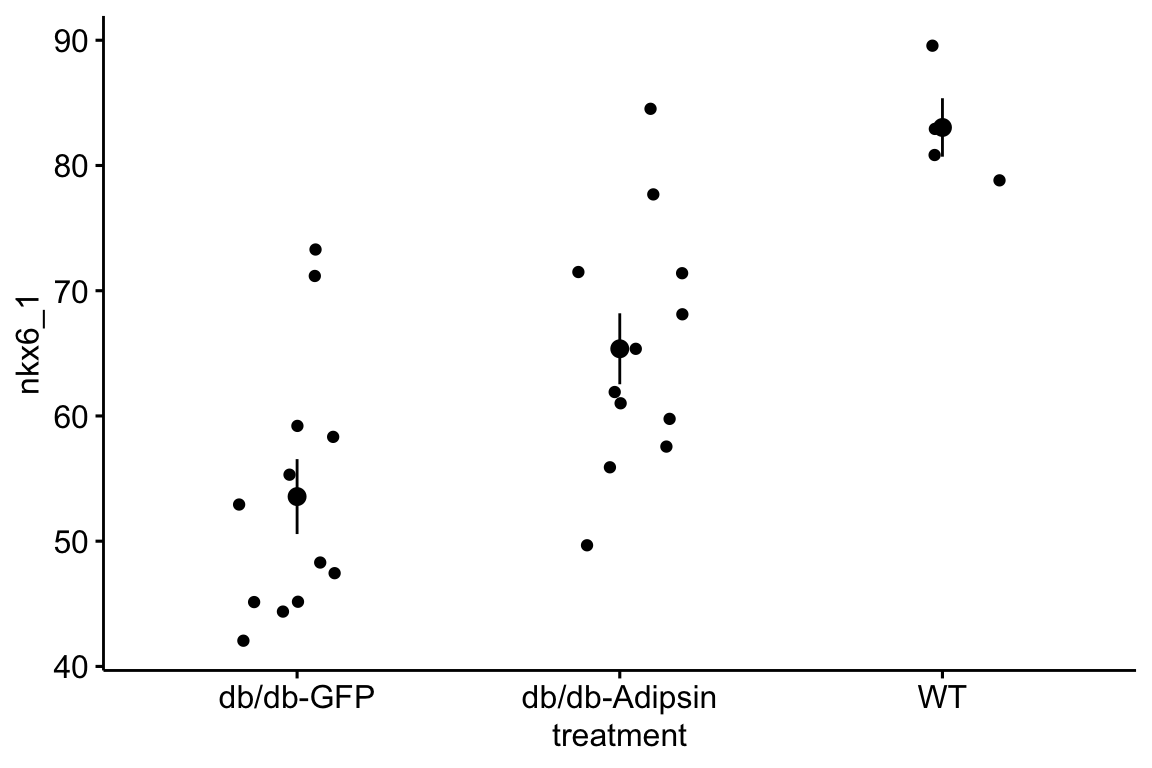
- Import and quick pretty-good-plot the data for Figure 3b of the PI3K paper. You will need to download and archive the Excel file for “Figure 3.” Store this within the “Suppression of insulin feedback enhances…” folder.
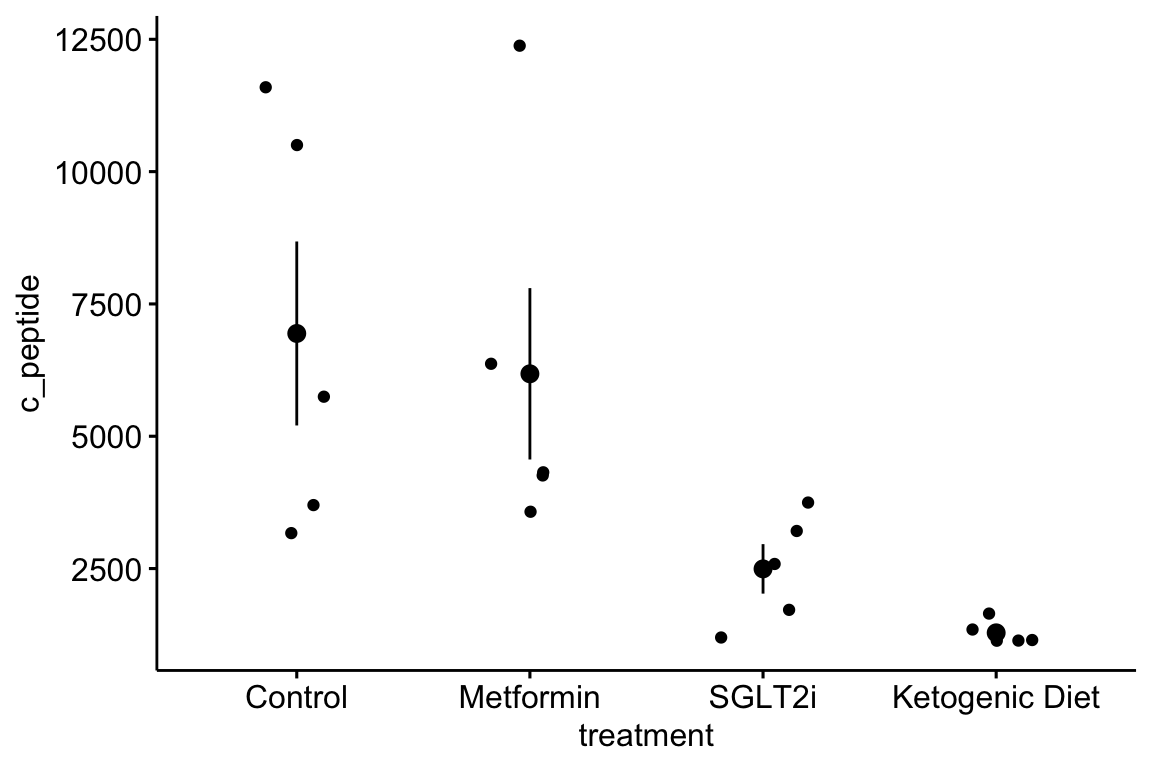
- The data are c-peptide levels in response to the treatments. C-peptide is cleaved from the pro-insulin polypeptide and circulates in the blood and is a marker of how much insulin is being produced by the beta cells of the pancreas.
- The data are in wide format, with each treatment group in a separate column. The data need to be melted into long format with a new column called “treatment.”
- Modify the code from exercise 1 to pretty-good-plot the data as in exercise 1.